Performance no React
Lucas Bittencourt / agosto 11, 2022
• 11min de leitura

Índices
- Introdução
- React Hook: useMemo
- React Hook: useCallback
- React: memo
- React: Por que utilizar a propriedade
keyem loops? - Bônus: Renderizações desnecessárias
Introdução
React é uma biblioteca JavaScript bastante performática. Por baixo dos panos, ele consegue previnir bastante dos erros de um desenvolvedor desatento durante o desenvolvimento. Mas, ainda sim, há cenários em que nosso código acaba comprometendo a performance de nossa aplicação.
Além disso, lidar com performace em React pode ser uma faca de dois gumes. Utilizar as técnicas de performance podem SIM piorar o desempenho da nossa aplicação, do que se tivesse deixado o React trabalhar sozinho. Então, é sempre bom ficar atento em todos os fluxos da aplicação, além de debugar sempre que possível.
Algoritmo de Reconciliação
No React, um componente pode ter vários componentes aninhados. Quando um componente é renderizado, toda sua hierarquia abaixo é renderizada junto.
Existe um algoritmo de diferenciação (diffing algorithm) por baixo dos panos, chamado de Algoritmo de Reconciliação (reconciliation), que está por trás da famosa renderização que ocorre nos componentes React.
Para entender o fluxo de renderização de um componente, podemos dizer que ele é dividido em 3 partes:
- Gera a Virtual DOM a partir do código JSX
- Compara a Virtual DOM com a DOM original (Aqui ocorre o diffing feito pelo Algoritmo de Reconciliação)
- Commita na DOM original somente as mudanças
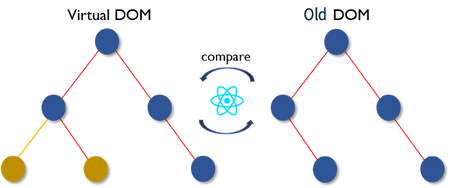
Agora que entendemos como funciona o algoritmo de reconciliação e o que ocorre por baixo dos panos em um fluxo de renderização no React, surgiu a seguinte dúvida: Por que fazer todo esse processo, ao invés de somente commitar a DOM virtual na DOM original de uma vez?
Aí que tá: Esse é um processo EXTREMAMENTE lento. Agora imagina renderizar o componente raíz da aplicação e commitar de uma vez toda a tela no DOM? Então sim. Compensa passar por esse processo trabalhoso.
Memoização
O React nos disponibiliza alguns métodos de performance que utilizam uma técnica chamada de memoização.
Para entender melhor como funciona este conceito, podemos dizer que é uma técnica que armazena em memória o retorno de funções "puras", para que não precisemos executar novamente aquela função.
No mundo da programação, temos o que chamamos de funções puras e impuras.
- Funções impuras são aquelas funções em que o resultado do retorno depende de algo externo, logo, seu retorno poderá não ser o mesmo sempre.
- Funções puras são funções independentes de valores externos, dependendo apenas de seus parâmetros. Logo, se passado os mesmos parâmetros, o resultado será sempre o mesmo.
Então, a memoização é utilizada em cima de funções puras. Se eu executei uma função pura que tem um processamento computacional consideravelmente pesado, por que vou executar novamente, se eu chamar com os mesmos parâmetros? Eu sei que o retorno será o mesmo, SEMPRE.
Com o React é a mesma coisa: Podemos memoizar valores (useMemo), funções (useCallback) e até mesmo componentes (memo). Mas, tome cuidado. Use apenas quando necessário, pois o custo de usar pode ser maior do que não usar. Lembre-se que ao usar, o React irá alocar memória para guardar essa informação e dispensar o garbage collector. Além de que envolve mais complexidade no código, já que será necessário saber do porquê essas funções estarem sendo usadas e confirmar que estão sendo usadas corretamente.
Igualdade referencial
No JavaScript, temos os tipos de dados primitivos e o tipo referencial. Por mais que tudo no JavaScript é objeto, podemos ter essa separação de primitivo e referencial.
Os tipos de dados primitivos, serão sempre iguais em um shallow compare (ou comparação rasa, famoso ===), porque 1 === 1. Sempre. Assim como "Lucas" será sempre === "Lucas". Agora faça o teste com os outros tipos primitivos.
Já no tipo de dado referencial, não. Se compararmos um objeto literal { name: "Lucas" } === { name: "Lucas" }, essa comparação sempre vai ser falsa. Assim como se compararmos o array ["Lucas"] === ["Lucas"] também será falso (e o mesmo vale para funções).
Por isso, em alguns casos precisaremos manter a igualdade referencial utilizando os hooks do React, como: useMemo e useCallback.
Lembrando que a gente mantém a igualdade referencial somente pro React lidar com isso internamente. Por exemplo: memoizamos uma função para passar no array de dependências de um useEffect para o React não triggerar aquela função novamente, já que funções também são diferentes referencialmente.
React Hook: useMemo
O useMemo é usado para memoizar VALORES. Sejam esses valores do tipo primitivo ou de referência (tirando funções, tem um hook somente para funções: useCallback).
Sintaxe:
const memoizedValue = useMemo(() => expensiveFunction, dependencies);
Existe duas razões para se utilizar o useMemo em seu código:
- Evitar re-cálculos pesados
- Manter a igualdade referencial
Evitando re-cálculos pesados
Como sabemos, todo componente no React é uma função (com exceção das classes, mas só muda a abstração). Logo, o processo de renderização de um componente é: executar a função. Então quer dizer que ao renderizar um componente, todo o código dentro deste componente será executado novamente! Desde a chamada dos hooks, instanciação de variáveis, instanciação de funções, até a criação do nosso DOM Virtual (retorno do nosso HTML -- JSX).
Logo, se em um cenário específico eu tenho o seguinte trecho de código:
const filteredList = filterList(myList);
Imagina que essa função filterList faça um cálculo MUITO pesado. Agora, sabemos que caso nosso componente renderize, essa função será chamada de novo, MESMO que não seja necessário -- nossa myList não sofreu alterações.
Para evitar isso, devemos usar o useMemo, como no seguinte trecho de código:
const filteredList = useMemo(() => filterList(myList), [myList]);
Por que manter a igualdade referencial?
Assim como no useCallback, existe 2 motivos para usarmos o useMemo para manter a igualdade referencial na nossa aplicação.
- Para usar a função como array de dependências em um
useEffect - Para passar a função para componentes filhos.
Explico melhor esses 2 cenários no tópico do useCallback abaixo.
React Hook: useCallback
Diferentemente do useMemo, que serve para memoizar um retorno de uma função, o useCallback está aqui para memoizar a própria função. E não, não importa o tamanho da função, a gente apenas quer manter a igualdade referencial daquela função pro React, internamente, saber lidar com aquela função e evitar re-renders ou chamadas de useEffect.
Sintaxe:
const memoizedFunction = useCallback(functionToMemoize, dependencies);
Quando usar o useCallback?
Há dois cenários em que devemos usar este hook:
- Para usar a função como array de dependências em um
useEffect
Como sabemos, o useEffect é triggerado quando um valor de seu array de dependências é alterado durante um novo render. Por baixo dos panos, ocorre o famoso shallow compare (ou comparação rasa, famoso ===).
Logo, se eu passo uma função no array de dependências, ela nunca será igual ao valor anterior pois ela foi re-criada em tempo de renderização, executando o useEffect toda vez que o componente for renderizado. E pior: caso o useEffect mude algum estado da aplicação dentro dele, ocorrerá loop infinito na aplicação, já que a mudança de estado irá forçar o componente a ser renderizado novamente, executando o useEffect e assim repetindo o processo.
- Para passar a função para componentes filhos.
Quando temos um componente memoizado, queremos pular a renderização deste componente quando o pai for renderizado. Mas, se não memoizarmos a função que está sendo passada para o filho, o memo vai falhar na comparação e vai mandar o componente ser todo renderizado novamente.
React: memo
Sabemos que, ao renderizar um componente, todos os filhos são renderizados por padrão. Também sabemos que esse pode ser um processo extremamente custoso pra nossa aplicação.
Quando um componente pai é renderizado e o filho não teve nenhuma de suas props alteradas, o componente em tela deveria ser o mesmo, não? Então Por que não simplesmente "pulamos" a renderização de um componente específico? É aí que entra o memo.
Sintaxe:
// memo(Component, diffing)
export default memo(function App() {
return (
<div>
<p>Olá, mundo!</p>
</div>
);
});
// ou:
export default memo(App);
Durante a renderização, o memo faz um shallow compare (ou comparação rasa, famoso ===) de suas novas props com as props antigas. Caso a comparação detecte que houve mudanças, ele renderiza o componente. Se não, ele pula a renderização.
Quando um componente é "pesado" e suas props não mudaram, este é um cenário perfeito para usar o memo. Mas preste atenção em um detalhe muito importante! Tenha certeza que as props tenham igualdade referencial. Muitas vezes não prestamos atenção, mas ao passar funções ou um tipo não primitivo como prop, estes nunca serão iguais aos anteriores, então o memo vai falhar e mandar renderizar o componente de qualquer jeito, sempre. Então, dê uma lida em useMemo e useCallback para entender melhor esses hooks.
React: Por que utilizar a propriedade key em loops?
Quando um componente é renderizado, é primeiro gerado a DOM Virtual. E em seguida, há uma comparação com a DOM original.
Sintaxe:
<div>
{list.map((item) => (
<p key={item.id}>{item.text}</p>
))}
</div>
Basicamente, o React utiliza o key para atualizar, adicionar, trocar ou remover um item da lista no DOM no momento da renderização, sem precisar commitar toda a lista de uma vez.
Imagine que eu tenho um array de 10 itens e que no JSX, eu retorno em cada índice uma <div />. Imagine agora, que na renderização seguinte ocorra uma troca de posição de um item, ou até mesmo a troca de valor de uma índice do array. Nesse cenário, o React não consegue saber para qual índice o item foi, já que os valores podem ser iguais, dentro do array. É aí que entra a propriedade key.
Sem essa propriedade, o React iria renderizar toda a lista novamente no DOM, causando problemas de performance. Quando utilizamos a propriedade key, o React vai saber, no momento da diferenciação (algoritmo de reconciliação), onde que ocorreu a mudança, e então só vai commitar na DOM original a mudança ocorrida dentro do array.
Por que não deveríamos usar a index do .map como key?
Sintaxe:
<div>
{list.map((item, index) => (
<p key={index}>{item.text}</p>
))}
</div>
Quando utilizamos a índice do .map, não garante confiabilidade. Imagina o seguinte cenário: Eu troco um item de índice 0 de lugar com o item de índice 5 no array. Ou seja, atualmente o item de key={0} está em primeiro na lista e o de key={5} está em sexto. Quando ocorre a troca, o item de key={5} deveria aparecer em primeiro na lista, mas como o index sempre vai ser sequencial, independente do item do array, pro React essa troca não aconteceu. Porém, ocorreu
Bônus: Renderizações desnecessárias
Agora que entendemos que um render pode ser custoso, vamos conhecer um possível cenário onde nossa aplicação acaba renderizando mais que o necessário. Temos o seguinte trecho de código:
import { useEffect, useState } from "react";
export default function App() {
const [repos, setRepos] = useState([]);
const [filteredRepos, setFilteredRepos] = useState([]);
const [search, setSearch] = useState([]);
useEffect(() => {
async function getRepos() {
try {
const response = await fetch(
"https://api.github.com/users/lucasgdb/repos"
);
const data = await response.json();
setRepos(data);
} catch (err) {
console.error(err);
}
}
getRepos();
}, []);
useEffect(() => {
if (search.length) {
setFilteredRepos(repos.filter((repo) => repo.name.includes(search)));
}
}, [search, repos]);
const handleChange = (event) => setSearch(event.target.value);
return (
<div>
<input placeholder="Buscar..." value={search} onChange={handleChange} />
<ul>
{search.length > 0
? filteredRepos.map((filteredRepo) => (
<li key={filteredRepo.name}>{filteredRepo.name}</li>
))
: repos.map((repo) => <li key={repo.name}>{repo.name}</li>)}
</ul>
</div>
);
}
No exemplo acima, note que toda vez que eu digito algo no input, o segundo useEffect é triggerado, alterando um estado no React. Sendo assim, mais uma renderização será lançada na fila. Pra gente, pode parecer ok, mas se formos analisar, esse segundo render é desnecessário. Não é necessário um estado derivado.
Estados derivados são estados criados a partir de outros estados. Como por exemplo
filteredRepos, criado a partir derepos.
Veja só:
import { useEffect, useState } from "react";
export default function App() {
const [repos, setRepos] = useState([]);
const [search, setSearch] = useState([]);
useEffect(() => {
async function getRepos() {
try {
const response = await fetch(
"https://api.github.com/users/lucasgdb/repos"
);
const data = await response.json();
setRepos(data);
} catch (err) {
console.error(err);
}
}
getRepos();
}, []);
const filteredRepos = repos.filter((repo) => repo.name.includes(search));
const handleChange = (event) => setSearch(event.target.value);
return (
<div>
<input placeholder="Buscar..." value={search} onChange={handleChange} />
<ul>
{search.length > 0
? filteredRepos.map((filteredRepo) => (
<li key={filteredRepo.name}>{filteredRepo.name}</li>
))
: repos.map((repo) => <li key={repo.name}>{repo.name}</li>)}
</ul>
</div>
);
}
Nós conseguimos criar o filtro em tempo de renderização. Isso vai fazer com que nosso componente seja renderizado apenas 1 única vez, ao digitar no input.
Ah, e de quebra dá pra mencionar: Caso o cálculo do filtro de repositórios fosse custoso, daria para usar o useMemo alí! E use memo! :D