Table of contents:
- Is Node.js single-threaded?
- CPU-bound vs. I/O-bound tasks
- Node.js event loop
- Node.js cluster
- Node.js child_process
- Node.js worker_threads
- Scaling Node.js with PM2
- When to use Node.js and when to avoid it
Is Node.js single-threaded?
Yes. Node.js is single-threaded, which means it handles tasks sequentially on one thread.
But, due to its non-blocking I/O behavior, Node.js Event Loop can efficiently handle multiple concurrent I/O-bound tasks.
In other hands, we can manage multi-threading in Node.js by using modules such as cluster, child_process,
worker_threads or process managers such as PM2.
CPU-bound vs. I/O-bound tasks
Node.js executes every line of code in the call stack. When a CPU-bound task is executed by the call stack, it blocks the main thread and next step will proceed only when the code is executed. So, when a heavy CPU-bound task is executed, it can impact the application performance.
Examples of CPU operations:
- Mathematical computation
- Image, Video and Audio processing
- Compilling or parsing code
- Artificial Intelligence
- Regular Expressions
- Cryptographic operations
When the executed code line is a I/O-bound task, Node.js event loop can handle this in a asynchronous way, without blocking the main thread. Instead, it will run in the background.
Examples of I/O operations:
- Network operations
- Database operations
- File system operations
- Stream operations
- E-mail operations
- Timers and delayed executions (although these are not strictly I/O-bound, they are non-blocking and handled asynchronously)
Node.js event loop
The event loop orchestrates asynchronous (non-blocking I/O) operations and manages the flow of events in the application. It enables the application to continue executing other code while I/O operations are in progress, preventing blocking and enhancing performance.
The Node.js event loop manages two types of callback queues: the Microtask queue and the Task queue (also known as the Macrotask queue). When an I/O-bound task is executed asynchronously by Node.js —often via libuv or the underlying OS— the task's callback is placed in one of these queues. Microtasks have higher priority than Macrotasks, meaning they are always executed before Macrotasks when both are available.
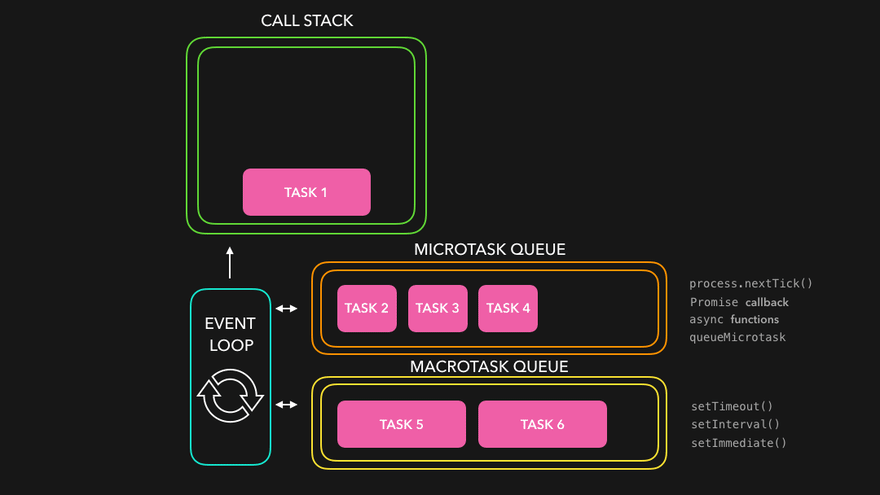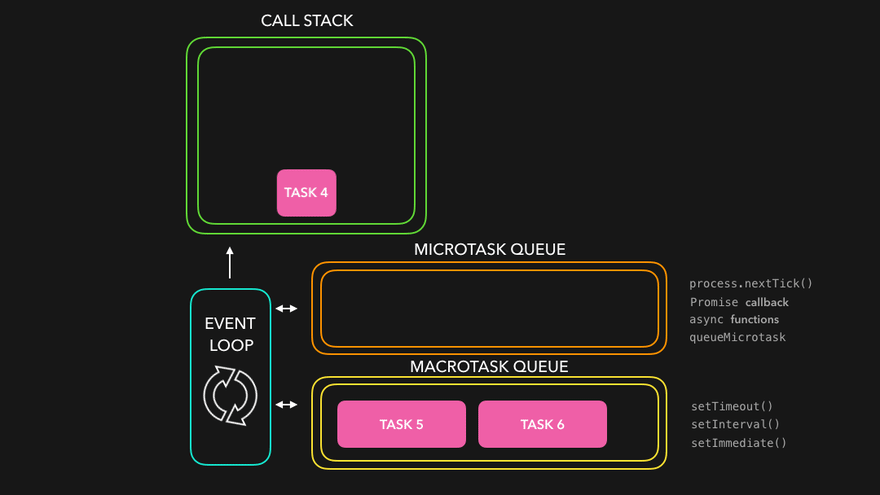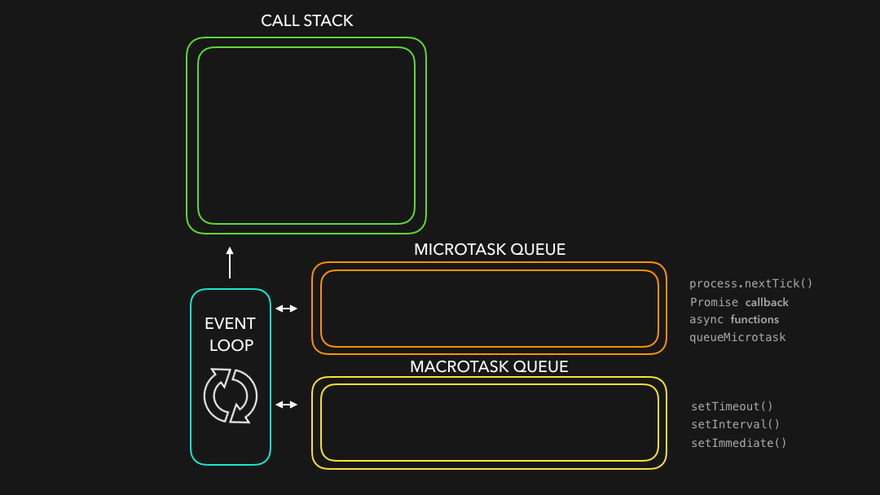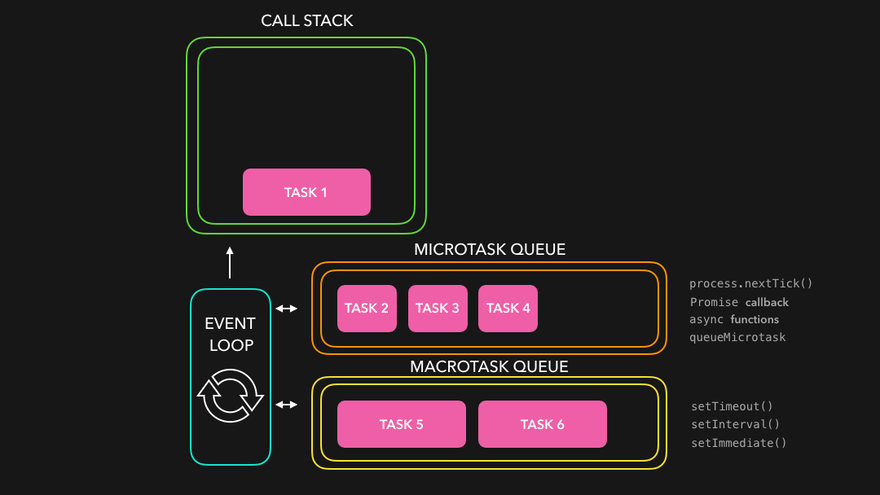
The Node.js event loop consists of 6 phases, with each phase responsible for executing specific types of callbacks.
Event loop phases:
- Timers: executes callbacks scheduled by
setTimeoutandsetInterval - Pending callbacks: executes I/O callbacks deferred to the next loop iteration
- Idle & prepare: Only used internally
- Poll: Retrieves new I/O events; executes I/O callbacks
- Check: executes callbacks scheduled by
setImmediate - Close callbacks: executes close callbacks (e.g.
socket.on('close', ...))
Detailed overview about Event Loop here
Node.js cluster
You can use Node.js cluster to take the advantage of multi-core systems by creating multiple instances of the same
application that can handle incoming requests concurrently. It is similar to child_process,
but specifically for scaling Node.js applications, as it shares the same port.
Example:
import cluster from "node:cluster";
import { createServer } from "node:http";
import { cpus } from "node:os";
if (cluster.isPrimary) {
console.log(`Primarily PID ${process.pid} is running`);
const numCPUs = cpus().length;
// Fork workers
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker, code, signal) => {
console.log(`Worker PID ${worker.process.pid} died`);
// Optionally, replace the dead worker:
cluster.fork();
});
} else {
// Workers can share the TCP connection
const server = createServer((_req, res) => {
res.writeHead(200);
res.end(`Hello World from PID ${process.pid}\n`);
});
server.listen(8000);
server.on("listening", () => {
console.log(`Worker PID ${process.pid} started`);
});
process.on("SIGTERM", () => {
console.log(`Worker PID ${process.pid} is shutting down...`);
server.close(() => {
console.log(`Worker PID ${process.pid} has closed all connections`);
process.exit(0);
});
});
}
Node.js child_process
You can use child_process to spawn separated processes with its own memory to handle CPU-heavy tasks.
Example:
import { fork } from "node:child_process";
// Fork a new child process to run the CPU-bound task
const child = fork("./child.ts");
// Listen for messages from the child process
child.on("message", (result) => {
console.log(`Result from child process: ${result}`);
});
// Send a start message to the child process
child.send("start");
child.ts:
// CPU-bound task: Calculating fibonacci sequence
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
// Listen for messages from the parent process (optional)
process.on("message", (msg) => {
if (msg === "start") {
const result = fibonacci(45); // Intensive CPU-bound task
process.send?.(result); // Send result back to the main process
}
});
Node.js worker_threads
You can use worker threads to execute CPU-bound tasks in parellel within the main thread.
Example:
import { Worker, isMainThread, parentPort } from "node:worker_threads";
if (isMainThread) {
console.log("Main thread event loop");
// Create a worker thread
const worker = new Worker(__filename);
worker.on("message", (message) => {
console.log("Received from worker:", message);
});
} else {
// Worker thread has its own event loop
console.log("Worker thread event loop");
// Send a message back to the main thread
parentPort?.postMessage("Hello from worker");
}
Scaling Node.js with PM2
PM2 is a daemon process manager that will help you manage and keep your application online 24/7. It provides a process management, monitoring and clustering feature. Additionally, PM2 includes an automatic load balancer that shares all HTTP[s]/Websocket/TCP/UDP connections between each spawned processes.
Installing
npm install pm2 -g
How to use
pm2 start app.js --name app_name -i max --interpreter node
Explaining
--name app_namespecifies the application's name-i maxspecifies the number of instances (or processes) you want to run--interpreter nodespecifies the interpreter (e.g.node,ts-node,tsx)
Example:
const { createServer } = require("node:http");
const server = createServer((_req, res) => {
res.writeHead(200);
res.end(`Hello World from ${process.pid}\n`);
});
server.listen(8000, (err) => {
if (err) {
console.error("Error starting server:", err);
process.exit(1);
} else {
console.log("Server listening on port 8000");
}
});
server.on("listening", () => {
console.log(`Worker ${process.pid} started`);
});
process.on("SIGTERM", () => {
console.log("Worker ${process.pid} is shutting down...");
server.close(() => {
console.log("Worker ${process.pid} has closed all connections");
process.exit(0);
});
});
When to use Node.js and when to avoid it
While Node.js is very performant at handling I/O-bound operations, it can struggle with CPU-bound tasks, as they tend to block the event loop and degrade performance.
Node.js is highly recommended for I/O-heavy workloads, such as real-time applications, API servers, and data streaming services. However, if your application involves heavy CPU-bound tasks, you can mitigate this by using the child_process module to offload tasks to separate processes. Alternatively, you can create a microservice dedicated to handling these CPU-intensive operations, which can be implemented in any language best suited for the job.